Come ottimizzare i siti di pagine singole per i motori di ricerca
Quando Google e altri motori di ricerca indicizzano i siti Web, non eseguono JavaScript. Questo sembra mettere i siti a pagina singola, molti dei quali si basano su JavaScript, con un enorme svantaggio rispetto a un sito web tradizionale.
Non essere su Google, potrebbe facilmente significare la morte di un'azienda, e questa scoraggiante scoraggiata potrebbe indurre il non informato ad abbandonare del tutto i siti di una sola pagina.
Tuttavia, i siti di una sola pagina in realtà hanno un vantaggio rispetto ai siti web tradizionali nell'ottimizzazione dei motori di ricerca (SEO) perché Google e altri hanno riconosciuto la sfida. Hanno creato un meccanismo per i siti a pagina singola non solo per indicizzare le loro pagine dinamiche, ma anche per ottimizzare le pagine in modo specifico per i crawler.
In questo articolo ci concentreremo su Google, ma altri grandi motori di ricerca come Yahoo! e Bing supportano lo stesso meccanismo.
In che modo Google esegue la scansione di un sito di una singola pagina
Quando Google indicizza un sito web tradizionale, il suo crawler web (chiamato Googlebot) prima scandisce e indicizza il contenuto dell'URI di primo livello (ad esempio, www.myhome.com). Una volta completato, segue tutti i collegamenti su quella pagina e indicizza anche quelle pagine. Segue quindi i collegamenti nelle pagine successive e così via. Alla fine indicizza tutto il contenuto sul sito e i domini associati.
Quando Googlebot tenta di indicizzare un sito a pagina singola, tutto ciò che vede nell'HTML è un singolo contenitore vuoto (in genere un tag div o body vuoto), quindi non c'è nulla da indicizzare e nessun link da sottoporre a scansione e indicizza il sito di conseguenza ( nella circolare circolare "cartella" sul pavimento accanto alla sua scrivania).
Se quella fosse la fine della storia, sarebbe la fine dei siti a pagina singola per molte applicazioni e siti web. Fortunatamente, Google e altri motori di ricerca hanno riconosciuto l'importanza dei siti a pagina singola e hanno fornito strumenti per consentire agli sviluppatori di fornire informazioni di ricerca al crawler che possono essere migliori rispetto ai siti Web tradizionali.
Come rendere la scansione di un sito di una sola pagina
La prima chiave per rendere eseguibile la scansione del nostro sito a pagina singola consiste nel rendersi conto che il nostro server può stabilire se una richiesta viene eseguita da un crawler o da una persona che utilizza un browser Web e risponde di conseguenza. Quando il nostro visitatore è una persona che utilizza un browser web, risponde normalmente, ma per un crawler, restituisce una pagina ottimizzata per mostrare esattamente al crawler quello che vogliamo, in un formato che il crawler può facilmente leggere.
Per la pagina iniziale del nostro sito, che aspetto ha una pagina ottimizzata per il crawler? Probabilmente è il nostro logo o altra immagine primaria che vorremmo visualizzare nei risultati di ricerca, alcuni testi ottimizzati per il SEO che spiegano cosa è o cosa fa il sito e un elenco di link HTML solo per quelle pagine che vogliamo indicizzare. Ciò che la pagina non ha è uno stile CSS o una struttura HTML complessa applicata ad esso. Né ha JavaScript né link ad aree del sito che non vogliamo che Google indicizzi (come le pagine di declinazione di responsabilità legale o altre pagine che non vogliamo che le persone inseriscano tramite una ricerca su Google). L'immagine sotto mostra come una pagina può essere presentata a un browser (a sinistra) e al crawler (a destra).
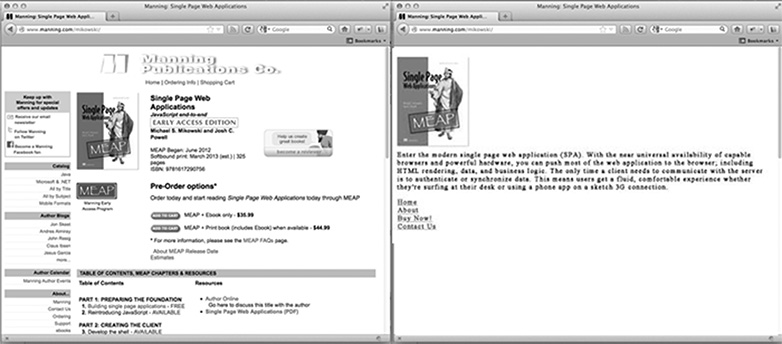
Personalizzazione del contenuto per i crawler
In genere, i siti di una singola pagina si collegano a contenuti diversi utilizzando un hash bang (#!). Questi collegamenti non sono seguiti allo stesso modo da persone e crawler.
Ad esempio, se nel nostro sito a pagina singola un link alla pagina utente appare come /index.htm#!page=user:id,123 , il crawler vedrebbe il #! e sapere di cercare una pagina Web con l'URI /index.htm?_escaped_fragment_=page=user:id,123 . Sapendo che il crawler seguirà il modello e cercherà questo URI, possiamo programmare il server in modo che risponda a quella richiesta con un'istantanea HTML della pagina che verrebbe normalmente visualizzata da JavaScript nel browser.
Quell'istantanea verrà indicizzata da Google, ma chiunque clicchi sulla nostra scheda nei risultati di ricerca di Google verrà indirizzato a /index.htm#!page=user:id,123 . Il codice JavaScript della pagina singola sostituirà da lì e renderà la pagina come previsto.
Ciò fornisce agli sviluppatori di pagine singole l'opportunità di personalizzare il loro sito specificamente per Google e in particolare per gli utenti. Invece di dover scrivere un testo che sia leggibile e attraente per una persona e comprensibile da un crawler, le pagine possono essere ottimizzate per ciascuna senza preoccuparsi dell'altra. Il percorso del crawler attraverso il nostro sito può essere controllato, consentendoci di indirizzare le persone dai risultati di ricerca di Google a una serie specifica di pagine di accesso. Ciò richiederà un maggiore lavoro da parte dell'ingegnere per lo sviluppo, ma può comportare grandi vantaggi in termini di posizione dei risultati di ricerca e di fidelizzazione dei clienti.
Rilevamento del web crawler di Google
Al momento della stesura di questo, Googlebot si annuncia come crawler al server effettuando richieste con una stringa user-agent di Googlebot / 2.1 (+ http://www.googlebot.com / bot.html) . Un'applicazione Node.js può controllare la stringa di questo agente utente nel middleware e restituire la home page ottimizzata per il crawler se la stringa dell'agente utente corrisponde. Altrimenti, possiamo gestire normalmente la richiesta.
Questo arrangiamento sembra come se fosse complicato da testare, dal momento che non possediamo un Googlebot. Tuttavia, Google offre un servizio per farlo per siti Web di produzione disponibili pubblicamente come parte dei suoi Strumenti per i Webmaster, ma un modo più semplice per testare è quello di spoofare la nostra stringa user-agent. Ciò richiedeva alcuni hackery da riga di comando, ma gli Strumenti per sviluppatori di Chrome rendono questo semplice come fare clic su un pulsante e selezionare una casella:
Apri gli Strumenti per sviluppatori di Chrome facendo clic sul pulsante con tre linee orizzontali a destra della Google Toolbar, quindi selezionando Strumenti dal menu e facendo clic su Strumenti per sviluppatori.
Nell'angolo in basso a destra dello schermo c'è un'icona di ingranaggi: fai clic su di esso e guarda alcune opzioni avanzate di sviluppo come disabilitare la cache e attivare la registrazione di XmlHttpRequests.
Nella seconda scheda, denominata Sostituzioni, fai clic sulla casella di controllo accanto all'etichetta Agente utente e seleziona un numero qualsiasi di agenti utente dal menu a discesa da Chrome, a Firefox, a IE, iPad e altro. L'agente Googlebot non è un'opzione predefinita. Per usarlo, seleziona Altro e copia e incolla la stringa utente-agente nell'input fornito.
Ora quella scheda si sta spoofando come un Googlebot e quando apriremo qualsiasi URI sul nostro sito, dovremmo vedere la pagina del crawler.
In conclusione
Ovviamente, diverse applicazioni avranno esigenze diverse in relazione a cosa fare con i web crawler, ma avere sempre una pagina restituita a Googlebot probabilmente non è sufficiente. Dovremo anche decidere quali pagine vogliamo esporre e fornire modi per la nostra applicazione per mappare l' URI _escaped_fragment_ = key = value al contenuto che vogliamo mostrare.
Potresti voler essere fantasioso e legare la risposta del server al framework front-end, ma di solito qui ho un approccio più semplice e creare pagine personalizzate per il crawler e inserirle in un file router separato per i crawler.
Ci sono anche molti altri crawler legittimi, quindi una volta modificato il nostro server per il crawler di Google, possiamo espanderci per includerli.
Costruisci siti di pagine singole? Come si eseguono i siti a pagina singola sui motori di ricerca? Fateci sapere che ne pensate nei commenti.
Immagine in primo piano / miniatura, cerca immagine via Shutterstock.